
Beyond the Hype: Exploring the True Potential of Autonomous Agents
Generative Agents, Auto-GPT, ChatDev - how close are we to AGI?


From Generative Agents and Auto-GPT to ChatDev and AutoGen, Large Language Models (LLMs) based autonomous agents have been the talk of the town in recent months. It's not surprising, given that autonomous agents are viewed by many as a significant step toward achieving artificial general intelligence (AGI), where AI systems can autonomously plan and execute tasks.
However, most of these autonomous agents are still in the experimental phase. They often require human intervention or exhibit unexpected behavior. We are undeniably in the early stages of development, with numerous unknowns in creating reliable and robust LLM agents.
So what are LLM agents?
An agent is defined as "a person who acts on behalf of another person or group." In the context of AI, an AI agent is assigned a task, like booking a flight ticket, and autonomously carries out that task, such as booking the flight and sending a confirmation email. LLM then enables us to assign tasks to AI agents using natural language.
Considering this definition, we realize that LLMs alone are insufficient because they possess knowledge about the world but lack the capability to execute tasks. Autonomous agents, on the other hand, must have the ability to:
Reason and plan, breaking objectives into sub-tasks and adapting to unexpected circumstances. For example, a flight booking agent must gather flight options, evaluate them based on user preferences, and request additional information if necessary, like timings or seat preferences.
Acquire the tools to interact with the external environment. For instance, a flight booking agent needs to access flight databases and navigate the booking process through a web browser.
In essence, autonomous agents can perform actions independently. But let's delve into a more technical perspective. Interestingly (or perhaps not), there is no universally accepted definition of LLM-based agents in the tech community. Nevertheless, we can use the following framework (proposed in a recent paper and similar to the definition by Lilian Weng from OpenAI) to understand them:
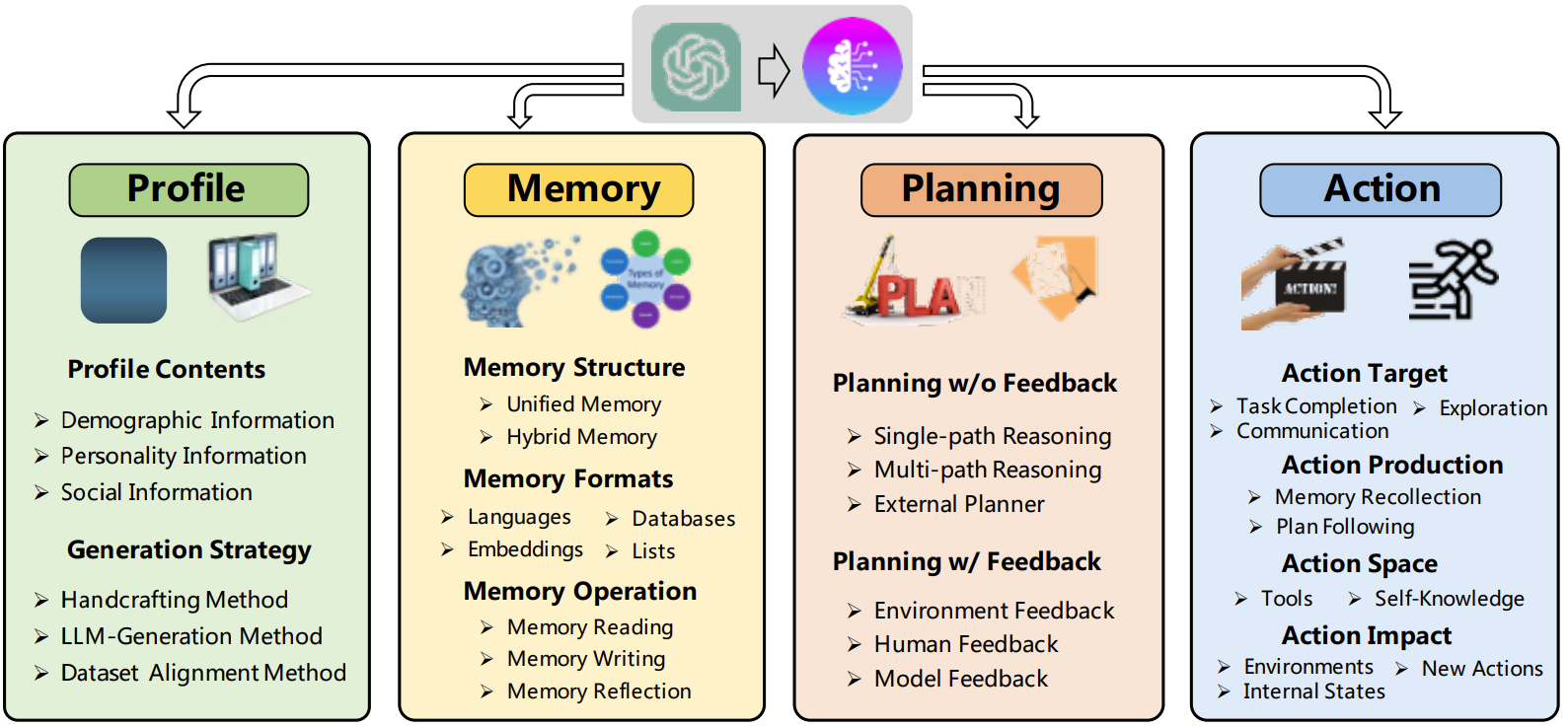
LLM-based autonomous agents can be broken down into four building blocks:
Profile: Identifying the agent's role and its influence on LLM behavior, as well as relationships between agents in a multi-agent environment. For instance, we can define the LLM's role, specifying whether it acts as a programmer or a writing assistant in the given prompt.
Memory: Enabling agents to store information and recall past actions, which informs their future behavior. The memory component encompasses both short-term memory, which is limited by the context window, and long-term memory, typically stored in an external vector database.
Planning: Equipping LLMs with the ability to mimic human reasoning by breaking down large objectives into smaller sub-goals, often using techniques like Chain of Thought (COT) and Tree of Thoughts (ToT). For example, prompt instructions can be added to guide LLMs to "Think step by step" or encourage them to generate reasoning paths.
Action: Translating decisions into actions through various tools, such as APIs and databases, to interact with the external environment.
Profile establishes the role of the agent whereas memory and planning enable it to navigate the dynamic environment before acting. This framework sheds light on why building autonomous agents can be difficult, as it is rather tricky to teach agents how to plan or when to use tool or handle memories.
What can we already do with LLM agents?
The possibilities are extensive.
LLM agents have made significant progress, moving beyond their initial stages of simply connecting with tools for web browsing or executing Python code. We are witnessing increasing innovation, particularly in the realm of multi-agent systems. Early projects involve deploying multiple LLM-based agents in virtual environments to simulate various scenarios, such as classrooms or broader societal settings. For instance, Generative Agents (see demo) and Agent Sims create virtual towns to simulate everyday life (e.g. having impromptu conversations and organizing parties), which proves valuable for social science experiments investigating social phenomena.
Another promising avenue involves employing multi-agent environments to establish a virtual workforce. Here, inter-agent communication and collaboration enhance the quality of LLM outputs. For example, ChatDev can swiftly develop software games like Gomoku or Flappy Bird in under seven minutes, for less than a dollar. This is achieved through role-playing within a software agent development agency, featuring specialized agents playing roles like CEO, CTO, and programmer. The latest frameworks, such as AutoGen, even incorporate human feedback into the collaboration process, potentially reducing software development costs and augmenting the workforce.

LLM-powered robotics is another intriguing area due to their planning capabilities and the capacity to control robots using natural language. In a recent paper, GPT-4V showcased the potential of combining vision and LLM agents to help robots plan navigation routes to complete task. GPT-4V was able to predict the subsequent actions including navigation and arm movement to “fetch something from the fridge”.

While these innovations are exciting, many of them remain in the proof-of-concept stage, with various limitations and challenges to address before reaching a production-ready, safe, and reliable state.
It's important not to underestimate the progress of LLM agents; they offer a glimpse of what can be achieved with agents and significantly enhance the capabilities of LLM, particularly in simpler tasks like type error correction or single-step workflows. Empowering LLM to reevaluate its approach and review output already provides value. However, it's still too early to confidently predict that agents can solve multi-step tasks in the near future.
What are the roadblocks / opportunities?
LLM-based agents need to be trusted - and the trust is driven by reliability and observability. Agents should ideally be 99% reliable due to their potential impact, and we must have the means to observe their thought processes, understand decision-making, and intervene when necessary. There is no easy way to achieve this: likely involving a combination of continuous refinement, breakthroughs in the underlying reasoning system, narrower use cases, and the development of a comprehensive tooling stack, including debugging and tracing.
That's actually one of the biggest issues with agents that, you know, go off and do longer range goals is that I have to trust, like, did they actually think through this situation? - Qiu Kanjun from Latent Space podcast: Why AI Agents Don't Work (yet)
Addressing memory management is essential to solve the finite context issue. The limited context length can hinder the inclusion of historical information, impacting decision-making in longer-range tasks. While retrieval augmented generation (RAG) has been instrumental in storing and retrieving long-term memories, the emergence of memory management startups like MemGPT holds promise.
Compute cost will continue to be a bottleneck. Training and evaluating LLM agents typically demand more extensive LLM function calls compared to training LLM models. Efficiency is key to scaling, with companies like Imbue leveraging large-scale GPU clusters in their training processes.
Lastly, community standards are gradually taking shape, with evaluation benchmarking and common protocols, such as the Agent Protocol for inter-agent communication. As agents mature and become more prevalent, questions regarding the identity, legal liabilities, governance, and regulations surrounding LLM agents will likely require a more standardized approach in the field.
Conclusion
Building an end-to-end autonomous agent is a challenging endeavor that may not come to fruition in the immediate future (> 3 years). Nonetheless, today's LLM-based agents have already taken a substantial leap forward in terms of their capabilities. As we look ahead, we can anticipate a wealth of forthcoming innovations across the whole agent ecosystem.
This is so well-researched and eye-opening! I think "narrower use cases" as you mentioned could be a way forward, so that it is easier to train, measure and optimize agents' performance in a defined solution space.