


Navigating the AI Chip Shortage
Build more chips or be more efficient - or go peer-to-peer?


The US has banned the export of AI chips to China, and the UK Prime Minister, Rishi Sunak, plans to allocate £100 million of taxpayer funds to invest in AI chips as part of the global race for computer power. Saudi Arabia has also invested $120 million in chips to build its own supercomputer. The arms race is now in full swing, and data compute is being hailed as the new oil, as phrased in the State of AI Report 2023.
The rise of Generative AI has led to unprecedented demands for the underlying hardware required for training and running foundation models, particularly for chips known as graphics processing units (GPUs), which have become the standard for AI applications. Researchers estimate that training OpenAI's GPT-3 costs $4 million, with an additional daily cost of $700,000 for running it.
The global rush has resulted in a critical shortage, with Nvidia and GPU operators such as Coreweave already fully booked for remaining of 2023. Both incumbents and startups are seizing the opportunity to create innovative solutions to tackle the problem, but it remains unclear how these efforts will unfold.
But why are companies using so many GPUs?
I believe ChatGPT is the culmination of two different, multi-decade trends: data and hardware. As well as a key invention: Transformers.
The era of Generative AI has been propelled by decades of advancements and breakthroughs in three core components: architecture, data, and compute (Charlie Guo wrote a great post on "Why now for GenAI”). Compute plays a pivotal role in both training, where models learn, and inference, where models make predictions. The training process is more computationally intensive due to gradient computation and the data size. However, inference costs can quickly accumulate, especially for popular products like ChatGPT, which handles billions of queries daily.
In this context, GPUs have emerged as the gold standard. Originally designed as specialized accelerators for video games and graphics development in movies and animation, GPUs began to used for machine learning in the 2000s, thanks to their parallel computing capabilities. Compared to CPUs, GPUs excel in parallelizing simple, decomposable instructions, such as matrix multiplications, enabling efficient distribution of tasks across GPU cores.
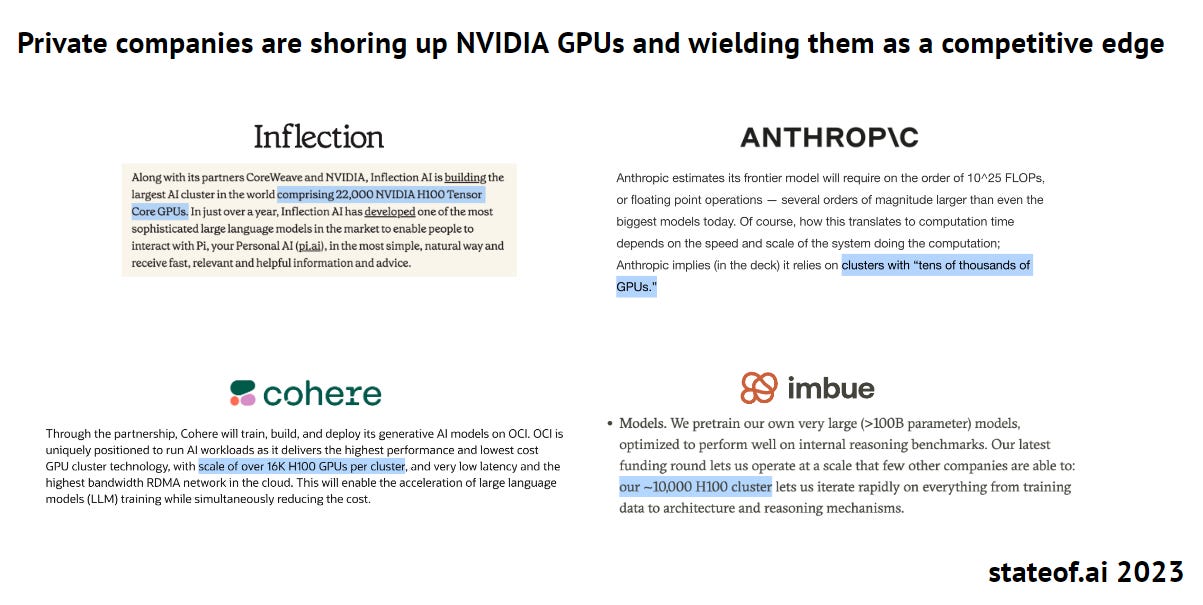
As a result, startups and researchers, particularly those training large foundation models, seek to secure the best GPUs (e.g., Nvidia A100s, H100s) to ensure scalability and cost-effectiveness for their models. GPUs not only optimize the hardware utilization and reduce operational expenses, but also accelerate the development and deployment of generative AI model. Hence, it comes as no surprise that some of the best-funded startups prioritize gaining access to GPUs as a competitive advantage.
How does the chip ecosystem work?
There are two primary methods for companies to access computer chips: (1) directly from a chip maker; or (2) renting access from a cloud service providers.
Purchasing directly from a chip maker, such as Nvidia: In this approach, companies would purchase GPUs and integrate them into their own infrastructure for running instances. This mitigates the risk of not being able to access chips from cloud service providers (CSPs) and often proves more cost-effective in the long term due to the substantial profit margins of CSPs, which can be as high as 61% or AWS and 72% for Microsoft cloud services. However, there are drawbacks to consider. Companies opting for this approach have to forgo the scalability advantages offered by the cloud and invest in additional technical capabilities to maintain their infrastructure.
Renting access from cloud service providers: Cloud giants like AWS and Google also purchase GPUs and integrate them into their infrastructure, but not solely for their in-house operations; they also offer these GPUs to cloud customers for rent. This option is typically favored by many startups that specialize in training large foundation models due to the substantial cost involved in establishing the infrastructure required for a GPU cluster. But given the ongoing GPU shortage, startups often collaborate with Nvidia and CSPs to secure dedicated GPU access and design GPU clusters optimized for their computational needs. For example, Nvidia and CoreWeave are currently assisting Inflection in installing a cluster that will incorporate 22,000 H100 GPUs. Notably, Nvidia has been allocating AI chips to emerging cloud players like Coreweave, diverting them from top cloud providers that are developing their own AI chips.
Potential solutions for the chip shortage?
Companies have been experimenting with various solutions to address the chip shortage, often securing substantial VC funding due to the potential size of the market. These solutions fall into three main categories:
Build more compute - increasing supply of ML-purposed computer chips
Use less compute - optimizing existing ML processes that reduces needs
Create a new supply model - building a peer-to-peer platform that enables compute renting
Building more computer chips
Given the enormous demand in the industry, with Nvidia's production fully booked in the short term, both tech giants and startups are striving to establish a foothold in the chip market. Tech giants such as OpenAI, Google, AWS, and others are actively exploring or developing their own in-house chips. However, many of these chip-making initiatives are still in their early stages, with examples like Meta scrapping its in-house chip development, and others facing similar supply challenges, as seen with Google's home-grown tensor processing unit (TPUs).
In addition to the tech giants, startups like Cerebras and Graphcore are directing their efforts toward developing specialized chips tailored for AI computing. Specialized chips are appealing due to their efficiency and effectiveness, as they are custom-built for specific tasks, such as handling complex workloads like deep learning models, as opposed to general-purpose GPUs. These insurgent chip makers have encountered mixed success in gaining traction within cloud providers and securing large-scale customers, which could be critical to business survival given the capital-intensive nature of the industry.
For instance, Cerebras recently announced a strategic partnership with G42 (Group42), an AI and cloud computing company, to build a 36 Exaflop AI supercomputer, representing a significant success. On the other hand, Graphcore is currently seeking new funds, and there is "material uncertainty" regarding its ability to continue as a going concern. Employees at Graphcore claims that their issues are are driven by a less mature software stack (in comparison to CUDA), which has hindered their ability to win over large-scale customers.
I think what you see with Graphcore is that they are not able to take these researchers and engineers in a smooth way from the Nvidia-dominated ecosystem into their own thing, these IPUs that they’re producing
Verdict: Nvidia is likely to maintain its dominant position in the foreseeable future due to its extensive ecosystem and software stack, making it challenging for others to replicate. However, if the chip shortage persists, Cerebras could emerge as a credible alternative, especially if a major cloud provider chooses to adopt Cerebras chips.
Optimizing existing ML training and inference processes
In 2023, the prevailing solutions for AI companies to enhance model performance and reduce costs have revolved around efficiency and optimization. Startups, including CentML, OctoML, and MosaicML (which was acquired by Databricks for $1.3 billion), have embraced a software-based approach to optimize model training workloads, ensuring they perform efficiently on target hardware. This optimization is often achieved through a compiler that translates programming language source code into machine code compatible with GPUs.
As a result of these efforts, businesses can lower their costs for cloud-based inference and make use of more economical hardware, such as previous GPU versions or even CPUs, while still achieving the same level of performance. A concrete example of this success can be seen in CentML, which claims to have optimized the Llama 2 model, enabling it to operate three times faster with Nvidia A10 GPU cards and reducing costs by a significant 60%.
Another strategy for optimization involves transitioning towards smaller models that are more cost-effective to train and operate. These models can be either general-purpose, like Microsoft's 13B Parameter Orca, which can emulate GPT-4, or use-case-specific models, often referred to as ASLMs (application-specific language models). A recent post by Generating Conversation highlights the increasing appeal of ASLMs, while also underscoring the practical challenges associated with fine-tuning costs, particularly in the context of ChatGPT.
Yes, GPT-3.5 fine-tuned is cheaper than GPT-4, but not by the 10 or 100x margin that’s possible. For ASLMs to take off, the base LLMs they’re built on need to get smaller, faster, and cheaper.
Verdict: Software-based optimization stands out as the likely short- to medium-term solution for most companies operating within a cost-constrained environment, enabling them to handle AI workloads even with less powerful chips. In the long term, a shift towards smaller model sizes and accelerated hardware performance is expected to become the standard.
Building a peer-to-peer platform that enables compute renting
In the earlier section, we delved into the chip ecosystem with chip makers and cloud service providers (CSPs) acting as intermediaries renting out compute access. But what if we could harness all the untapped compute power, ranging from data center and gaming GPUs to ASICs, through a peer-to-peer marketplace? Think of it as an "Airbnb for compute." where owners of these resources are incentivized with financial rewards for their compute usage.
The primary advantage of a peer-to-peer marketplace lies in its potential to disintermediate large cloud providers with substantial profit margins, while simultaneously tapping into the vast reserves of underused or unused idle compute resources. Consequently, this approach significantly reduces compute costs, while also democratizing access for a broader spectrum of users, including students and independent researchers, beyond the few well-funded startups and large enterprises.
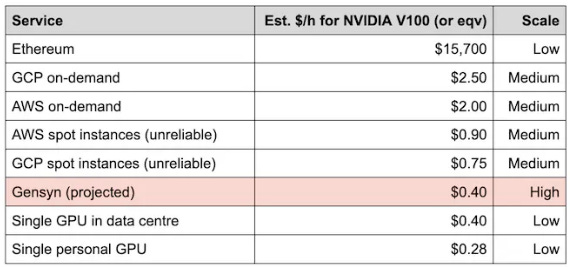
While the concept of peer-to-peer computing is enticing, it does bring about several technological challenges. These challenges encompass issues like data privacy concerns (how can companies be willing to share sensitive enterprise data for training such models?), difficulties related to parallel computing (how can researchers effectively train foundation models with compute resources distributed globally?), and verification challenges (how can we ensure that the training work is actually being executed?), among others.
Most projects, such as Gensyn, are still in the experimental phase as they grapple with these practical challenges. Based on current development, it is evident that machine learning researchers will need to adapt their work methods to enable decentralized models to function effectively. This adaptation may involve actions like splitting their models into parts and distributing them to GPUs with fast interconnects when necessary, and ensuring that tasks are tailored to fit within each device or solver for effective training. In the long term, decentralization could present a potential avenue to enhance compute availability, albeit not following the conventional operational methods.
We have gone down this path of centralized clusters being effective, and we are slowing the progress because it is much harder to create a bigger cluster, Maybe it is time to walk back the path and try another one: to connect all the devices and build over that, to explore that path. (Ben Fielding, Co-founder of Gensyn)
Verdict: While there is a strong desire to make GPU accessible to everyone, a peer-to-peer approach is only feasible for smaller-scale usage by students or researchers, as opposed to large-scale training, at least in the short term. Achieving broader adoption would necessitate a fundamental shift in the way machine learning training is currently conducted.
Conclusion
The current state of compute shortage is unlikely to be resolved in the short term, as well-funded startups, large cloud providers, and enterprises are likely to continue choosing Nvidia chips, considered the best-in-class option. However, the emergence of alternative chip makers and optimization techniques should make switching to other options a more feasible choice, which is especially important for expanding access to a broader community.