


Paths towards building a general reasoning engine
Review of the current perspectives: LLM scaling, RLAIF, new architectures on reasoning


The last two weeks in AI have been filled with both drama and memes, starting with OpenAI's leadership changes and followed by ongoing speculation about the reasons behind Sam's removal. The recent Reuters article brought to light OpenAI's internally named Q*, described as a "powerful artificial intelligence discovery that (researchers) said could threaten humanity." This revelation has sparked new theories and speculations.
In my decade spent on AI, I've never seen an algorithm that so many people fantasize about. Just from a name, no paper, no stats, no product. (Jim Fan on X)
While I won't delve deeply into the drama and hypotheses, it appears that various theories converge on the idea that the next generation of AI models will possess reasoning and planning capabilities, despite differing approaches. Here, I aim to highlight the different schools of thought that could drive the next wave of innovations.
Emergent capabilities from LLM scaling and multimodality
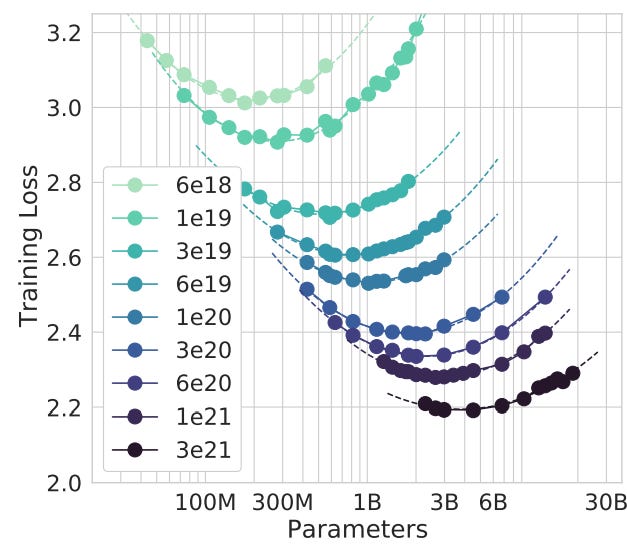
LLM scaling has played a crucial role in the development of transformer-based language models. The incorporation of more high-quality data and computational power has not only improved the accuracy and performance of LLMs but has also given rise to emergent capabilities, including reasoning. This perspective is affirmed in the case of GPT-4, where it demonstrates evidence of reasoning capabilities from its performance in bar and neurosurgery exams or general deductive reasoning.
Two intriguing areas that can support LLM scaling are the emergence of synthetic data and multimodality training. Synthetic data has the potential to generate substantial volumes of high-quality datasets to support model training, especially as the availability of high-quality data may become limited. On the other hand, multimodality training involves integrating visual data into the training process, supporting further emergent behaviors. This is critical given a significant portion of our knowledge extends beyond language alone.
While I believe there is still some runway for "free intelligence" through conventional scaling practices, it remains to be seen how effective this approach is in developing mathematical reasoning and a common-sense understanding of the world.
Self-improvement from RLAIF
Reinforcement learning (RL) involves rewarding the model for specific behaviors, and some RL-based AI systems, like AlphaGo, have demonstrated their capability for planning, where the reward criterion is straightforward (winning the game). The question now is how we can generalize a similar RL approach for natural language reasoning.
Nathan Lambert and Jim Fan, in their perspectives on Q*, propose a similar approach where we could:
Simulate tree-like reasoning paths using existing techniques like Tree of Thoughts or Graph of Thoughts.
Establish a reward system to evaluate each reasoning step within the path through Process-supervised Reward Models (PRMs), a separate model specifically for evaluation, rather than focusing solely on the end output.
These RL approaches seem reasonable, and we've observed results for mathematical reasoning (as seen in the "Let’s Verify Step by Step" paper), Imbue is also developing similar reasoning training based on a corpus of coding data. The key proposition of such RL models lies in the AI-enabled evaluation process, suggesting the potential for continuous self-improvement, similar to AlphaGo.
The initial proof of concepts should be in areas like math and code, where clear reasoning logic is present. We should then explore how well the reward model can be adapted, considering the potential significant leap required for natural language reasoning.
New architecture for reasoning models
The third camp argues that the current LLM architecture may not suffice to imbue AI models with reasoning capabilities, even with sufficient scaling and RL. New deep-learning architectures are required to enable breakthroughs.
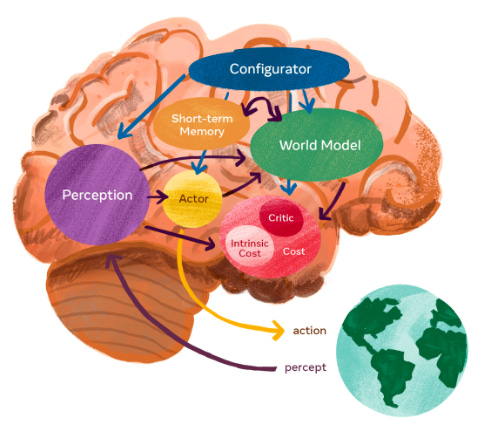
Yann Lecun, Meta's chief AI scientist, advocates for the "world model view," which draws inspiration from how animals and humans develop common sense-like capabilities. This development occurs through observing the physical world and distinguishing between what is possible and impossible in their mental model of the world. For example, when someone drops a pen, we can predict the pen's fall, although not its precise position. Current models like ChatGPT and Dall-E predominantly focus on predicting exact pixels rather than capturing the abstract representation of events, such as the falling of a pen. Prioritizing this abstract representation enables AI models to anticipate and plan subsequent actions and their effects more effectively.
Nevertheless, these new architectures are still in the early phases of development, encountering both architectural and training challenges. In the long term, the world model view is likely to emerge as a critical component of intelligence. However, it remains unclear whether it will entirely replace current LLM architectures.
Conclusion
Planning capabilities will undoubtedly be core components of future LLMs, and attaining a self-supervised model will represent a significant stride in the space. It is genuinely fascinating to witness the convergence of various approaches, such as the amalgamation of conventional LLMs with AlphaGo-style algorithms. The approaches mentioned are not mutually exclusive, and it is highly probable that a future LLM will embody a combination of the three.